



より高品質なデータで より高精度なAIを構築
2011年に設立されたNexdataは、世界的に有名なAIトレーニングデータサービスプロバイダーです。Nexdataは超大規模なトレーニングデータセットを持ち、柔軟なAIデータ収集、データアノテーションなどカスタマイズサービスを提供しています。10年以上のノウハウを活かし、世界中1万社以上の企業にAIモデルのパフォーマンス向上を支援してきました。
jp
Please fill in your name
Mobile phone format error
Please enter the telephone
Please enter your company name
Please enter your company email
Please enter the data requirement
Successful submission! Thank you for your support.
Format error, Please fill in again
Confirm
The data requirement cannot be less than 5 words and cannot be pure numbers
世界のAI大手企業、ベンチャー企業・スタートアップ、大学研究機関から信頼されます。













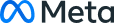
すぐに使える最新のデータセットにアクセスし、ビジネスの成長を促進しましょう。











Nexdataはグローバルなデータ処理工場とプロのアノテーターを20,000人以上整備しており、音声、画像、ビデオ、点群、テキストなどのオンデマンドデータアノテーションサービスをサポートしています。
独自のヒューマン・マシン・インタラクティブ半自動アノテーションプラットフォームは、より競争力のあるAI製品を構築するお手伝いをします。

3D 点群アノテーションツール

音声アノテーションツール

リモートセンシング向けたツール

動画アノテーションツール

2D画像アノテーションツール

テキストアノテーションツール

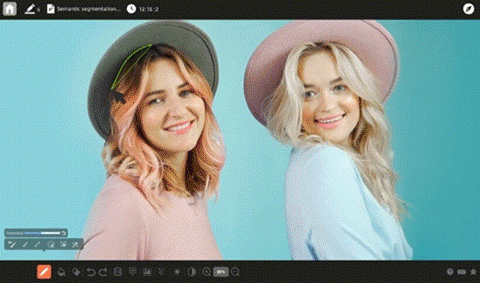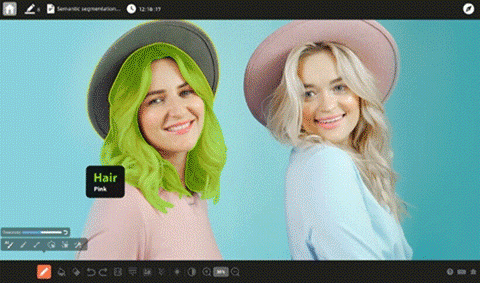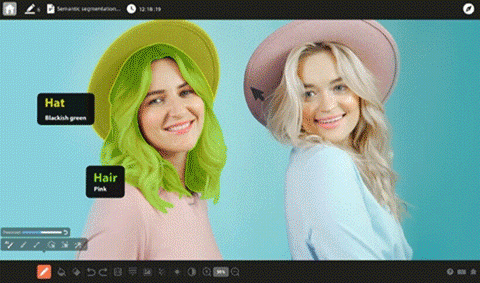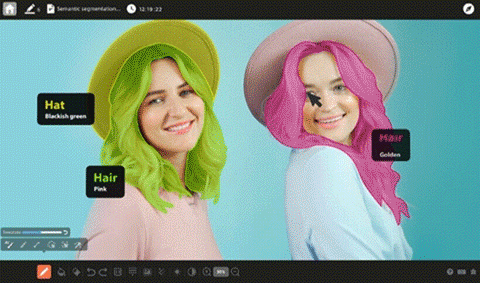
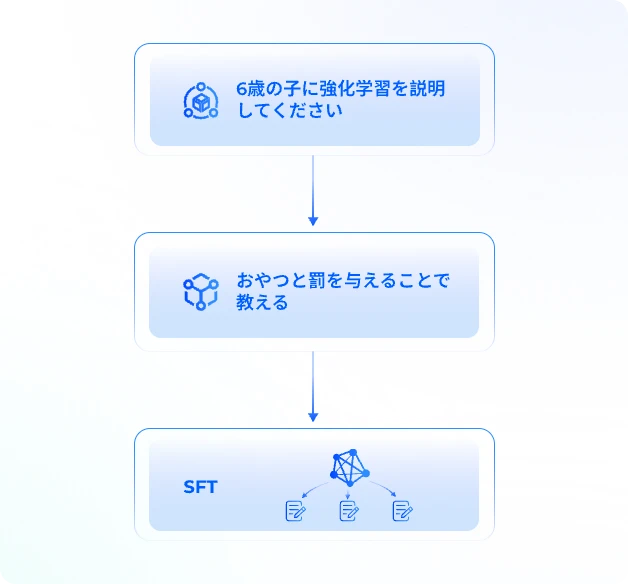
当社のデータサービスは、生成AI開発の各段階におけるお客様のAIイニシアチブの成長を加速。
ヒントとアウトプットのアノテーションにより、モデル最適化のための高品質な教師ありファインチューニングデータを作成します。
SFTで学習されたモデルによって生成された複数のアウトプットを、お客様が提供したルールに従って手動でランク付けしたり、多要素スコアリングをします。
悪意のある質問や有害な可能性のある質問など敵対的な攻撃を想定し、モデルの訓練と検証を行います。
Nexdataは車内センシングから車外知覚までカバーするデータを提供し、自動運転ソリューションのあらゆるニーズにお応えします。

Nexdataは1000を超える既製データセットを保有しており、すぐに納品可能です。また、頭のポーズ、視線、表情認識、ジェスチャー検出など、車内アプリケーションのためのデータカスタマイズサービスも提供しています。
3D点群データアノテーション、データ収集、プライベート導入可能なアノテーションプラットフォームなどADAS/AV向けにカスタマイズデータソリューションを提供します。

マルチレベル品質検査、ISO9001品質管理認証により、高品質のデータを納品します。

ヒューマンマシンインタラクションと半自動アノテーションをサポートし、一人あたりアノテーション効率を30%以上向上させます。

当社はGDPRおよびCCPAの規制に準拠しており、当社と共有されるすべてのデータを保護します。

データ収集、カスタマイズサービス、データプラットフォームをカバーする包括的なセキュリティ・パイプラインにより、データ・セキュリティを徹底します。
既製品データセットは無料サンプル入手可能ですか?
お客様のご要望に応じて、既製品データセットを提案しています。もちろん、データの詳細、サンプルなどご提供可能です。
既製データセットの安全対策はどうなっていますか?
全てのデータセットは弊社版権で取り扱っています。データの提供元からAIモデル・機械学習開発に使われる許可を得ています。お客様には安心してお使いいただけます。
日本語の方言音声データ収集は対応できますか?
はい。関西弁、九州弁、東北弁など、地域ごとのアクセントに対応した収集が可能です。
学術研究向けの無料データセットは提供していますか?
はい、提供しています。Nexdataでは、大学や研究機関など世界中の非営利組織を対象に、「AIデータ支援研究プログラム」を実施しています。このプログラムを通じて、コンピュータビジョンや音声認識など、さまざまな分野における高品質なトレーニングデータセットを無償で提供し、AI研究の発展をサポートしています。ご要望に応じて、既存の提供範囲外のデータセットについても、個別にご相談承ります。

Nexdata、JSAI2026(第40回人工知能学会全国大会)にスポンサーとして出展

Nexdata、AI Market ExCon 2026に出展

第2回「MLC-SLM Challenge」応募開始!多言語会話音声理解の発展に向けた2,100時間の大規模データセットを公開

一人称視点データセットでフィジカルAIを加速|10万時間実世界操作データがロボティクス開発の課題を解決

フィジカルAIのデータ収集が簡単に、 実機テレオペ・UMI・Egocentric動画の4方式を開発者の視点で比較し、開発現場で使えるデータ作成方法を解説

Nexdata、総計25億円投資でフィジカルAIデータ収集工場を拡張、基盤モデル向けデータセット提供やEgo-centricデータ収集も対応












