目標設定
大規模言語モデル(LLM)は、言語理解・生成のタスクにおいて強力な基盤モデルとして機能しています。近年では、LLMを自動音声認識(ASR)、オーディオキャプション、音声対話モデルなどの最先端分野の音声言語処理タスクに適用する研究が多くなっています。
現実世界の会話音声データは、自然な一時停止・中断、話者の重複、多様な会話スタイルなど、人間のコミュニケーションの複雑さを捉えているため、LLMベースの音声対話モデルの開発に不可欠です。しかし、多言語環境の音声認識研究において、データ不足が大きな課題となっています。
現実世界の会話型音声は、多言語でダイナミック、かつ文脈に富んだ環境における高精度なAIシステムの構築や、音声対話が主要なコミュニケーションモードとして機能する次世代AI対話システムの開発に欠かせないです。
したがって、本ワークショップ・コンテストは、高精度な多言語会話音声言語モデルの構築に挑み、現実世界における多言語会話音声データセットを作成することで、音声認識の発展に寄与致します。
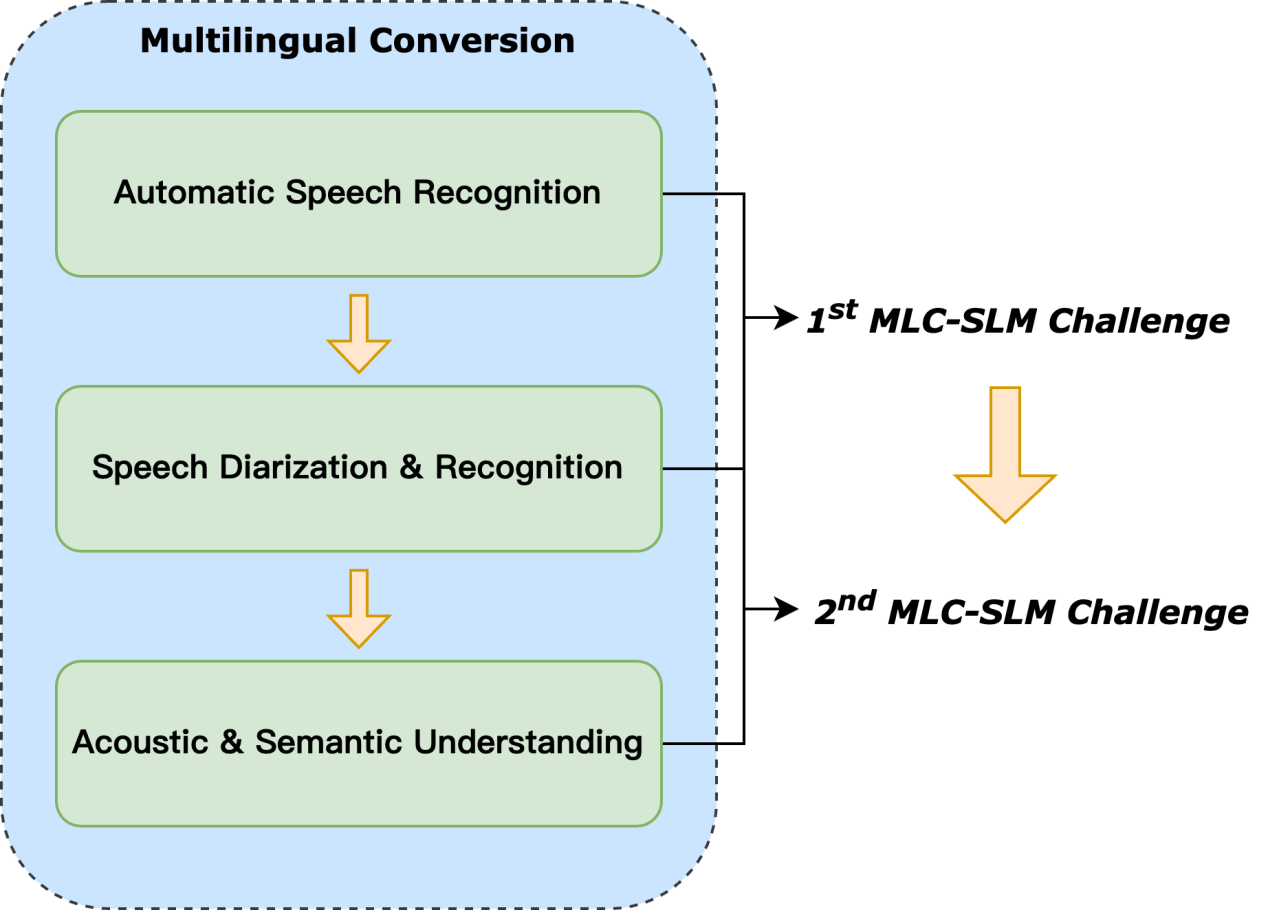
タスク設定・評価
このイベントは2つのタスクで構成されており、どちらも参加者に音声言語モデルの開発を探求することを求める:
タスク1:多言語会話型音声認識モデルの開発
目的: 多言語 LLM ベースのASRモデルの開発。
参加者には、会話ごとにオラクルセグメンテーションが提供されます。
このタスクでは、多言語環境での文字起こしの精度の最適化に焦点を当てています。
タスク2:多言語会話音声のダイアライゼーションと認識
目的:話者のダイアライゼーション(誰がいつ話しているかを特定する)及び認識(音声の文字起こし)の両方のシステム開発。
評価中に事前情報は提供されません(たとえば、事前にセグメント化された発話や話者ラベルなど)。
システムの設計・実装に柔軟性をもたらすため、パイプラインベースのシステムとエンドツーエンドのシステムの両方が推奨されます。
タスクIでは、異なる言語間の単語誤り率(WER)または文字誤り率(CER)を用いてシステム性能を評価します。
タスクIIでは、ダイアライゼーションエラーレート(DER)、およびtcpWERまたはtcpCERと呼ばれる最小並べ替えWERまたはCERに基づいて性能が評価されます。DERは、オラクル注釈とダイアライゼーション結果の間の最良の話者ID順列を決定するために採用されます。次に、録音内の同じ話者に属する認識結果と参照を連結して、tcpWERまたはtcpCERを計算します。すべての投稿は、tcpWERまたはtcpCERに従ってランク付けされます。
重要な日付(AOE時間)
2025年3月10日 登録開始
2025年3月15日 トレーニングデータ発表
2025年4月1日 開発セットとベースラインシステムのリリース
2025年5月15日 評価セットリリースとリーダーボード公開
2025年5月30日 リーダーボードの締め・論文提出ポータルのオープン(CMTシステム)
2025年6月15日 論文提出期限
2025年7月1日 採択通知
2025年8月22日 ワークショップ開催日
データセットの説明
トレーニングセット
チャレンジデータセットは、英語(en)、フランス語(fr)、ドイツ語(de)、イタリア語(it)、ポルトガル語(pt)、スペイン語(es)、日本語(jp)、韓国語(ko)、ロシア語(ru)、タイ語(th)、ベトナム語(vi)の約11言語で構成されています。
各録音は、ランダムに割り当てられたトピックに関する2話者の会話音声で構成されています。
会話は自然で流暢であり、各トピックについて意味のある対話をしています。
静かな室内環境で、iPhoneなどのデバイスを使用して録音したものです。
各録音は、音声認識および話者ダイアライゼーションシステム開発のためのオラクルセグメンテーションおよび話者ラベルを提供します。
タスクIとタスクIIは同じトレーニングセットを共有します。
英語のデータセットは、イギリス英語、アメリカ英語、オーストラリア英語、インド英語、フィリピン英語など、さまざまな地域の約500時間の録音から構成されています。その他の言語はそれぞれ約100時間で、合計約1500時間の多言語会話音声データとなっています。
このデータセットは、多言語会話音声言語モデル(MLC-SLM)の訓練と評価のための豊富なリソースを提供するように設計されており、言語の多様性、話者の多様性、文脈理解の課題に対応しています。
| 言語 | データ規模(時間) | 言語分類 | サンプリング・レート | 説明 |
| 英語 | 500 | | | アメリカ、イギリス、フィリピン、オーストラリア、インドの5つのアクセントの英語を収録。多様な性別と年齢、自然な会話スタイル。単語誤り率は2%以下。 |
| 100 | アメリカ英語 | 16K | |
| 100 | イギリス英語 | 16K | |
| 100 | フィリピン英語 | 16K | |
| 100 | オーストラリア英語 | 16K | |
| 100 | インド英語 | 16K | |
| フランス語 | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。単語の誤り率は2%以下。 |
| ドイツ語 | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。単語の誤り率は2%以下。 |
| イタリア語 | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。単語の誤り率は2%以下。 |
| 日本語 | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。文の誤り率は5%以下。 |
| 韓国語 | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。文の誤り率は5%以下。 |
| ポルトガル語(ヨーロッパ) | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。単語の誤り率は2%以下。 |
| ロシア語 | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。単語の誤り率は2%以下。 |
| スペイン語(スペイン) | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。単語の誤り率は2%以下。 |
| タイ語 | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。単語の誤り率は3%以下。 |
| ベトナム語 | 100 | | 16k | 録音は携帯電話で行い、レコーダーは身近な話題をいくつか選び、それぞれについてスムーズで自然な会話を録音する。話し手の性別や年齢は様々。単語の誤り率は2%以下。 |
開発セット
開発セット(Dev)はトレーニングセットと同じ設定ですが、各言語で約4時間の録音が含まれています。タスクIとタスクIIは、同じ開発セットを共有します。
評価セット
タスクごとに異なる評価セットを採用し、Eval_1 と Eval_2 とします。具体的には、Eval_1にはオラクルタイムスタンプと話者ラベルが含まれ、WER/CERを用いて評価されます。Eval_2では、タイムスタンプや話者ラベルが提供されないため、認識前に長い録音をセグメント化するための話者ダイアライゼーション(SD)システムが必要となります。
参加者は、データ使用同意書に署名し、登録フォームに送信することで、データセットにアクセスすることができます。送信後、データのダウンロードリンクがEメールに送信されます。
ルール
すべての参加者は、チャレンジの対象となるために以下のルールを遵守しなければなりません。
外部リソースの使用: トラックIとトラックIIの両方において、外部データセットと事前学習済みモデル(音声基礎モデルとLLMを含む)の使用が許可されます。利用される外部リソースは、すべての研究グループが自由にアクセスできるものでなければならず、最終的なシステムレポートに明記されなければなりません。
データ補強: リリースされたトレーニングセットでは、データの拡張が許可されており、ノイズや残響の追加、速度の摂動、音色の修正などが含まれるが、これらに限られるものではないです。
評価セットの使用禁止: どのような形であれ、コンプライアンスに反する形で評価セットを使用することは固く禁じられています。これには、モデルの微調整やトレーニングに評価セットを使用することが含まれるが、これに限られるものではないです。
マルチシステムフュージョン: タスクIとタスクIIのいずれにおいても、参加者はシステムフュージョンを使用することはできません。提出される結果は、結果融合ではなく、単一のモデルから導き出されたものでなければなりません。
提出要件: すべての参加者は、自身のシステムを提出する必要があります。提出物には、最終結果、モデル、最終結果を得るための推論を直接実行できるDockerなどが含まれます。詳細な提出方法は、ベースライン実装の公開後にお知らせします。なお、参加は確認したがファイルを提出しなかったチームとその所属機関名は公開します。
主催者の解釈: 主催者は、本ルールの最終的な解釈を行う権利を有します。特別な事情がある場合は、主催者が必要に応じて解釈を調整します。
その他のトピック
チャレンジシステムの説明に加え、参加者は革新的な発見、実践的なケーススタディ、将来を見据えたアイデアを紹介する研究論文を提出することが奨励されます。関心のあるトピックは以下の通りですが、これらに限定されるものではありません:
新しいアーキテクチャとアルゴリズム: SLMを訓練するための新しいアーキテクチャとアルゴリズムの開発。
オーディオデータ処理パイプライン: SLMを訓練するための多様なインターネットデータの収集を容易にする、生の音声データを処理するための革新的なパイプライン。
自然で感情豊かな音声生成: 対話システム向けに、より自然で感情表現豊かな会話音声を生成するためのアルゴリズム。
マルチターン会話履歴の活用: 認識やダイアライズの結果を向上させるためにマルチターン会話履歴を利用するアプローチ。
評価技法とベンチマーク: SLMの評価に特化した革新的な評価技術やベンチマーク。
新しいデータセット: 音声言語モデルのトレーニングのための、実データと合成データの両方を含む新しいデータセットの作成。
データへのアクセスと使用
登録された参加者は、トレーニングおよびテストのデータセットにアクセスすることができます。参加者は、データ使用同意書(下記参照)に署名し、守秘義務に同意し、データ保護同意書を遵守しなければなりません。データセットは、ワークショップの課題の目的にのみ使用され、再配布やその他の使用は固く禁じられています。不正アクセスからデータ を保護することは各参加者側の義務となります。
参加登録
参加には登録が必要です。 署名済みのデータ使用同意書をアップロードし、登録フォームに記入してください。チャレンジは2025年3月10日に開始します。
その他、登録に関するお問い合わせは下記までお願いいたします: [email protected]
論文投稿ガイドライン
1. チャレンジ論文:
a. 参加者は、短い技術説明論文を1つ提出しなければならないです(チームが両方のタスクに参加した場合も同様)。
b. 長さ: 内容2~4ページ+参考文献1ページ。
c. 内容の要件:
i. 提出書類の正確性と規則遵守にアクセスするための明確なシステム説明。
ii. 使用したオープンソースのデータセットとモデル、データ補強戦略、モデルアーキテクチャ、トレーニング構成などの再現性の詳細。
iii. アブレーション分析により、方法の有効性が実証されていること。
d. すべてのチャレンジ参加者は、ワークショップで講演またはポスターを発表することが期待されます。
2.チャレンジ以外の論文:
a. 長さ: 内容4ページ+参考文献1ページ。
b. トピック: チャレンジウェブサイトに掲載されているトピックを含むが、これに限定されません。
3. オーサーキット:
すべての投稿には、提供された Interspeech 2022 LaTeX オーサーキット (https://www.interspeech2022.org/files/IS2022_paper_kit.zip) を使用してください。 なお、我々は2022年インタースピーチ・オーサー・キットを使用し、シングル・ブラインド・レビューを行います。
4. 投稿ポータル
a. CMT conference system経由で論文を投稿してください。
b. 本大会の査読プロセス管理には、Microsoft CMTサービスを使用しました。このサービスはマイクロソフト社から無償で提供され、Azureクラウドサービスやソフトウェア開発・サポートにかかる費用を含め、すべての費用をマイクロソフト社が負担します。
賞金
賞金総額:20,000ドル
本大会上位入賞チームへの賞金(各タスク):
1位:5,000ドル
2位:3,000ドル
3位:2,000ドル
会場
ロッテルダム・アホイ・コンベンションセンター(オランダ・ロッテルダム)
委員会
Lei Xie、教授、西北理工大学(中国)
Shinji Watanabe、准教授、カーネギーメロン大学(米国)
Eng Siong Chng、教授、南洋理工大学(シンガポール)
Junlan Feng、IEEEフェロー兼チーフサイエンティスト、中国移動(中国)
Shuai Wang、研究科学者、深圳ビッグデータ研究所
Khalid Choukri、局長、局長欧州言語資源協会事務局(フランス)
Qiangze Feng、共同創業者兼データサイエンティスト、Nexdata(米国)
Daliang Wang、データサイエンティスト、Nexdata(米国)
Hexin Liu、博士研究員、南洋理工大学(シンガポール)
Pengcheng Guo、博士課程学生、西北工業大学(中国)
Bingshen Mu、博士課程学生、西北工業大学(中国)
Zhaokai Sun、修士課程学生、西北工業大学(中国)