[{"@type":"PropertyValue","name":"データ規模","value":"1,000枚(基礎編集データ500枚、専門編集データ500枚)"},{"@type":"PropertyValue","name":"収集の多様性","value":"請求書の内容、編集タイプ、フォーマットにおいて多様性を確保"},{"@type":"PropertyValue","name":"収集機材","value":"スキャナー"},{"@type":"PropertyValue","name":"フォーマット","value":"PDF形式およびJPEG形式(PDFから変換)の2種類で保存"},{"@type":"PropertyValue","name":"データ要件","value":"請求書に含まれる会社名、住所、氏名、電話番号、FAX番号などの個人・企業に関する情報はすべて仮想情報へ置換されており、実在の情報は含まれていません"},{"@type":"PropertyValue","name":"正確率","value":"収集要件に基づき、データの正確率は95%以上"}]
{"id":1841,"datatype":"1","titleimg":"https://jp.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp","type1":"147","type1str":null,"type2":"150","type2str":null,"dataname":"1,000枚OCR向け日本語請求書データセット","datazy":[{"title":"データ規模","content":"1,000枚(基礎編集データ500枚、専門編集データ500枚)"},{"title":"収集の多様性","content":"請求書の内容、編集タイプ、フォーマットにおいて多様性を確保"},{"title":"収集機材","content":"スキャナー"},{"title":"フォーマット","content":"PDF形式およびJPEG形式(PDFから変換)の2種類で保存"},{"title":"データ要件","content":"請求書に含まれる会社名、住所、氏名、電話番号、FAX番号などの個人・企業に関する情報はすべて仮想情報へ置換されており、実在の情報は含まれていません"},{"title":"正確率","content":"収集要件に基づき、データの正確率は95%以上"}],"datatag":"B2B,Japanese Invoices","technologydoc":null,"downurl":null,"datainfo":null,"standard":null,"dataylurl":null,"flag":null,"publishtime":null,"createby":null,"createtime":null,"ext1":null,"samplestoreloc":null,"hosturl":null,"datasize":null,"industryPlan":null,"keyInformation":null,"samplePresentation":[{"name":"00001.jpg","url":"https://storage-product.datatang.com/damp/product/instructions_zh/20260107150937/00001.jpg?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=gOMj0y0fUBHEILEauhLW36gMW5s%3D","intro":"","size":156247,"progress":100,"type":"jpg"},{"name":"00002.jpg","url":"https://storage-product.datatang.com/damp/product/instructions_zh/20260107150937/00002.jpg?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=dOGcwHK7DAojM%2Btxo7%2BNxyJxzpU%3D","intro":"","size":186713,"progress":100,"type":"jpg"},{"name":"00539.jpg","url":"https://storage-product.datatang.com/damp/product/instructions_zh/20260107150937/00539.jpg?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=Y6n%2BuIp59k2YojIAEVVaKYPkX98%3D","intro":"","size":278489,"progress":100,"type":"jpg"}],"officialSummary":"本データセットは、日本語の請求書画像1,000枚を収録した高品質なOCR学習用データです。基礎編集データ500枚と専門編集データ500枚から構成され、請求書の内容、編集方式、フォーマットにおいて十分な多様性を確保し、実際の業務で使用される帳票に近い構成となっています。画像内に含まれる会社名、住所、氏名、電話番号、FAX番号などの個人・企業情報はすべて仮想データに置換された匿名加工済み情報であり、プライバシーに配慮しています。本データは、日本語請求書の検出、OCRによる文字認識、帳票構造解析、キー情報抽出、エンドツーエンド型Document AIシステムの開発など、幅広いAI研究開発用途に活用可能です。","dataexampl":null,"datakeyword":["日本語OCRデータ","AI-OCR学習データ","請求書OCR学習用データ","日本語帳票データ"],"isDelete":null,"ids":null,"idsList":null,"datasetCode":null,"productStatus":null,"tagTypeEn":"Data Type,Language","tagTypeZh":null,"website":null,"samplePresentationList":null,"datazyList":null,"keyInformationList":null,"dataexamplList":null,"bgimg":null,"datazyScriptList":null,"datakeywordListString":null,"sourceShowPage":"ocr","dataShowType":"[{\"code\":\"0\",\"language\":\"ZH\"},{\"code\":\"1\",\"language\":\"ZH\"},{\"code\":\"2\",\"language\":\"EN,JP\"},{\"code\":\"3\",\"language\":\"EN\"},{\"code\":\"4\",\"language\":\"JP\"}]","productNameEn":"1,000 Images – Japanese Invoices Collection Data","BGimg":"","voiceBg":["/shujutang/static/image/comm/audio_bg.webp","/shujutang/static/image/comm/audio_bg2.webp","/shujutang/static/image/comm/audio_bg3.webp","/shujutang/static/image/comm/audio_bg4.webp","/shujutang/static/image/comm/audio_bg5.webp"],"firstList":[{"name":"00612.jpg","url":"https://storage-product.datatang.com/damp/product/instructions_zh/20260107150937/00612.jpg?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=l34495mf4xzSfCM5s3D68%2FxzVts%3D","intro":"","size":404979,"progress":100,"type":"jpg"}]}
https://jp.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp
[{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/instructions_zh/20260107150937/00001.jpg?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=gOMj0y0fUBHEILEauhLW36gMW5s%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/instructions_zh/20260107150937/00002.jpg?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=dOGcwHK7DAojM%2Btxo7%2BNxyJxzpU%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/instructions_zh/20260107150937/00539.jpg?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=Y6n%2BuIp59k2YojIAEVVaKYPkX98%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/instructions_zh/20260107150937/00612.jpg?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=l34495mf4xzSfCM5s3D68%2FxzVts%3D"}]
1,000枚OCR向け日本語請求書データセット
日本語OCRデータ
AI-OCR学習データ
請求書OCR学習用データ
日本語帳票データ
本データセットは、日本語の請求書画像1,000枚を収録した高品質なOCR学習用データです。基礎編集データ500枚と専門編集データ500枚から構成され、請求書の内容、編集方式、フォーマットにおいて十分な多様性を確保し、実際の業務で使用される帳票に近い構成となっています。画像内に含まれる会社名、住所、氏名、電話番号、FAX番号などの個人・企業情報はすべて仮想データに置換された匿名加工済み情報であり、プライバシーに配慮しています。本データは、日本語請求書の検出、OCRによる文字認識、帳票構造解析、キー情報抽出、エンドツーエンド型Document AIシステムの開発など、幅広いAI研究開発用途に活用可能です。
このデータセットは、商用利用や研究目的などに役立つ有償のデータセットです。著作権ありの既製データセットは、AIプロジェクトの飛躍的なスタートに役立ちます。
![仕様]()
データ仕様
データ規模
1,000枚(基礎編集データ500枚、専門編集データ500枚)
収集の多様性
請求書の内容、編集タイプ、フォーマットにおいて多様性を確保
フォーマット
PDF形式およびJPEG形式(PDFから変換)の2種類で保存
データ要件
請求書に含まれる会社名、住所、氏名、電話番号、FAX番号などの個人・企業に関する情報はすべて仮想情報へ置換されており、実在の情報は含まれていません
正確率
収集要件に基づき、データの正確率は95%以上
![サンプル]()
サンプル
![おすすめデータセット]()
おすすめデータセット
よくあるご質問

日本語OCRデータは、どのような形式・内容で提供されていますか?

手書き文字、帳票、商品ラベル、看板、公共文書など、実際の業務・生活シーンを想定した多様なデータを提供しています。すべてのデータセットには、行レベル・文字レベルのバウンディングボックスとテキスト転写が含まれ、用途に応じて柔軟にご利用いただけます。各データには詳細な仕様書とサンプルも同梱しており、事前にデータの特徴や適用可能性をご確認いただけます。
英語・日本語など多言語混在の帳票データも収集できますか?
はい、可能です。日本、アメリカ、中国、韓国など主要国を含むグローバルパートナー網を活用し、お客様の指定する業種・地域・フォーマットの実在帳票を現地で収集します。収集と並行して、ネイティブスピーカーによる高精度なアノテーションを即時実施できる体制を整えており、多言語混在文書や業界特化フォーマットにも柔軟に対応します。
多言語や業界特化データにも対応していますか?
はい。日本語(標準語・方言含む)に加え、英語、中国語、韓国語など12言語以上の自然シーンOCRデータを提供しています。製造、物流、小売、金融、公共サービスなど業界別のデータ構成も可能で、お客様のユースケースに最適なデータセットを迅速にご提案・提供いたします。
cb8ef4d7-f6f7-4e3d-84f0-3018f33a1a5a





 データ仕様
データ仕様 サンプル
サンプル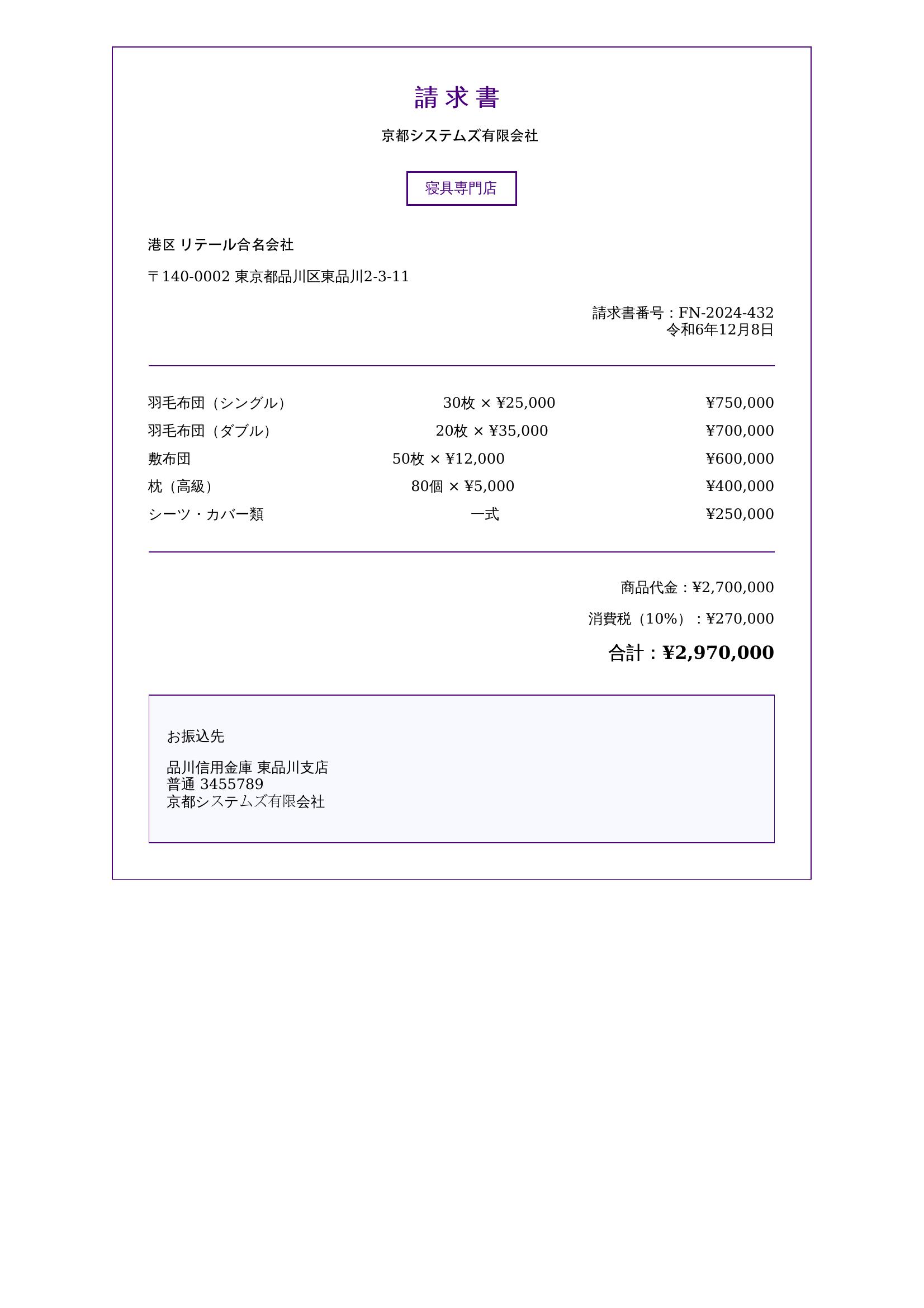

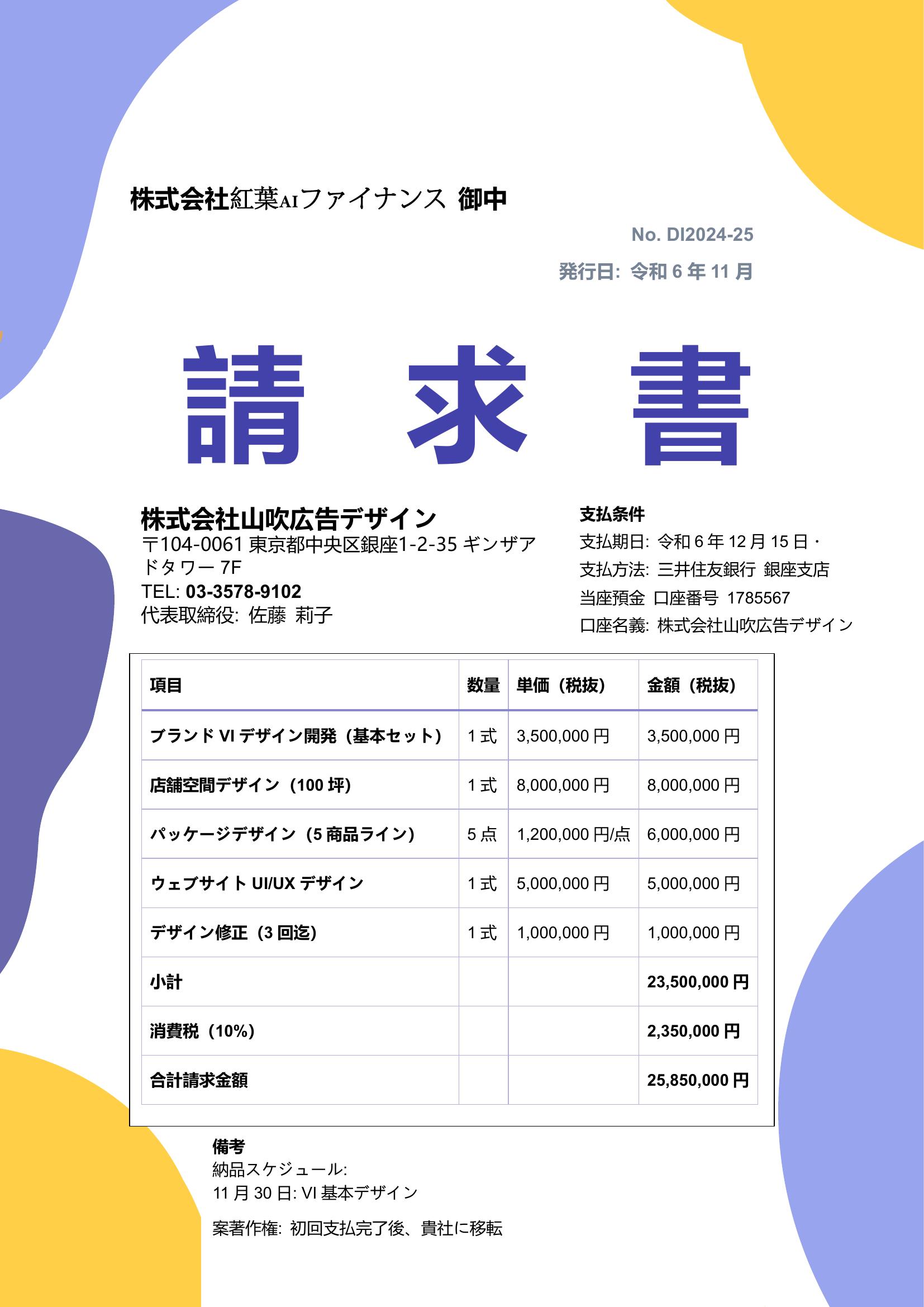
 おすすめデータセット
おすすめデータセット




