[{"@type":"PropertyValue","name":"内容","value":"質問、回答、カテゴリ、作成日時、ユーザーなどを含む"},{"@type":"PropertyValue","name":"データ規模","value":"質問数840万件、単語数23億語。回答2,700万件・76億語;感謝(質問者から回答者へ)1,550万件・17億語;補足説明210万件・3億6,000万語"},{"@type":"PropertyValue","name":"特徴","value":"Q&Aテキストデータ、プラットフォームの認可および著作権は明確です"},{"@type":"PropertyValue","name":"言語","value":"日本語"},{"@type":"PropertyValue","name":"フォーマット","value":"JSON"}]
{"id":1840,"datatype":"1","titleimg":"https://jp.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp","type1":"226","type1str":null,"type2":"227","type2str":null,"dataname":"800万件QA日本語対話データセット","datazy":[{"title":"内容","content":"質問、回答、カテゴリ、作成日時、ユーザーなどを含む"},{"title":"データ規模","content":"質問数840万件、単語数23億語。回答2,700万件・76億語;感謝(質問者から回答者へ)1,550万件・17億語;補足説明210万件・3億6,000万語"},{"title":"特徴","content":"Q&Aテキストデータ、プラットフォームの認可および著作権は明確です"},{"title":"言語","content":"日本語"},{"title":"フォーマット","content":"JSON"}],"datatag":"Q&A,Text,Japanese","technologydoc":null,"downurl":null,"datainfo":null,"standard":null,"dataylurl":null,"flag":null,"publishtime":null,"createby":null,"createtime":null,"ext1":null,"samplestoreloc":null,"hosturl":null,"datasize":null,"industryPlan":null,"keyInformation":null,"samplePresentation":[{"name":"1.png","url":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/1.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=suJVU5qEJZI7cFfSmGbb%2FEH3O%2Fc%3D","intro":"","size":93090,"progress":100,"type":"jpg"},{"name":"2.png","url":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/2.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=8VyLeLdVdYOPK5uOxWCTPVy%2B17k%3D","intro":"","size":138876,"progress":100,"type":"jpg"},{"name":"3.png","url":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/3.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=TfchG2iN3SSpSSlkWCnK%2FwdA2Qw%3D","intro":"","size":87528,"progress":100,"type":"jpg"}],"officialSummary":"日本 Q&Aプラットフォームのテキスト解析・処理データ。質問、回答、カテゴリ、作成日時、ユーザーなどを含む。データは継続的に更新される。4月25日時点で質問数840万件、単語数23億語。回答2,700万件・76億語;感謝(質問者から回答者への謝意)1,550万件・17億語;補足説明210万件・3億6,000万語。本データセットはLLMトレーニングやRLHF学習などのタスクに活用可能。","dataexampl":null,"datakeyword":["日本語LLMデータ","日本語テキストデータ","日本語QAデータセット"],"isDelete":null,"ids":null,"idsList":null,"datasetCode":null,"productStatus":null,"tagTypeEn":"Type","tagTypeZh":null,"website":null,"samplePresentationList":null,"datazyList":null,"keyInformationList":null,"dataexamplList":null,"bgimg":null,"datazyScriptList":null,"datakeywordListString":null,"sourceShowPage":"llm","dataShowType":"[{\"code\":\"0\",\"language\":\"ZH\"},{\"code\":\"1\",\"language\":\"ZH\"},{\"code\":\"2\",\"language\":\"EN,JP,PT,DE,KO,FR,ES\"},{\"code\":\"3\",\"language\":\"EN\"},{\"code\":\"4\",\"language\":\"JP\"}]","productNameEn":"Japanese OKWAVE Q&A platform Text Parsing and Processing Data","BGimg":"","voiceBg":["/shujutang/static/image/comm/audio_bg.webp","/shujutang/static/image/comm/audio_bg2.webp","/shujutang/static/image/comm/audio_bg3.webp","/shujutang/static/image/comm/audio_bg4.webp","/shujutang/static/image/comm/audio_bg5.webp"]}
https://jp.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp
[{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/1.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=suJVU5qEJZI7cFfSmGbb%2FEH3O%2Fc%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/2.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=8VyLeLdVdYOPK5uOxWCTPVy%2B17k%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/3.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=TfchG2iN3SSpSSlkWCnK%2FwdA2Qw%3D"}]
800万件QA日本語対話データセット
日本語LLMデータ
日本語テキストデータ
日本語QAデータセット
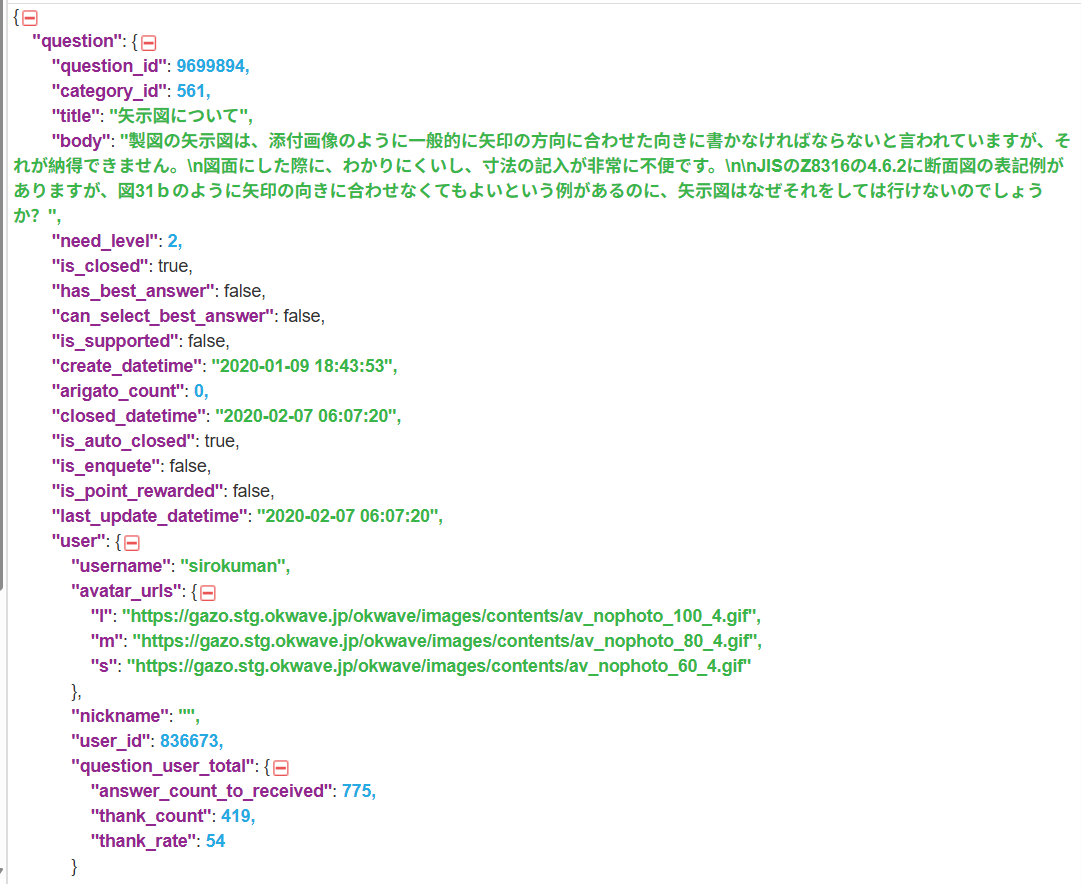
日本 Q&Aプラットフォームのテキスト解析・処理データ。質問、回答、カテゴリ、作成日時、ユーザーなどを含む。データは継続的に更新される。4月25日時点で質問数840万件、単語数23億語。回答2,700万件・76億語;感謝(質問者から回答者への謝意)1,550万件・17億語;補足説明210万件・3億6,000万語。本データセットはLLMトレーニングやRLHF学習などのタスクに活用可能。
このデータセットは、商用利用や研究目的などに役立つ有償のデータセットです。著作権ありの既製データセットは、AIプロジェクトの飛躍的なスタートに役立ちます。
![仕様]()
データ仕様
内容
質問、回答、カテゴリ、作成日時、ユーザーなどを含む
データ規模
質問数840万件、単語数23億語。回答2,700万件・76億語;感謝(質問者から回答者へ)1,550万件・17億語;補足説明210万件・3億6,000万語
特徴
Q&Aテキストデータ、プラットフォームの認可および著作権は明確です
![サンプル]()
サンプル
![おすすめデータセット]()
おすすめデータセット
よくあるご質問

大規模言語モデル学習用としてどのような分類・構造化データがありますか?

Nexdata の LLM データセットには、指示追従型(SFT)、試験問題、論文、画像キャプション・動画キャプションなど、多種多様なテキスト・ジャンルが含まれています。日本語以外も対応できる多言語・複数ドメインで、業界ごとの応用にも対応可能です。
日本での利用に際して、著作権やライセンスの問題はありませんか?
すべてのデータは自社版権で提供され、即時納品可能かつ安全・承認済みです。品質保証も万全で、安心してご利用いただけます。
大規模データはすぐに使えますか?カスタマイズは可能ですか?
はい、既製データセットはすぐに納品可能です。また、ニーズに応じたカスタマイズサービスも提供しており、コスパ良く効率的に導入できます。
51e7b06c-776e-475d-abb0-429eeb703629





 データ仕様
データ仕様 サンプル
サンプル

 おすすめデータセット
おすすめデータセット




